

Distributed Computing – verteiltes Rechnen für effiziente digitale Infrastrukturen

Distributed Computing (dt. „verteiltes Rechnen“) ist heute aus der digitalen Lebens- und Arbeitswelt nicht mehr wegzudenken. Wer ins Internet geht und eine Google Suche startet, nutzt bereits Distributed Computing. Verteilte Systemarchitekturen prägen auch viele Geschäftsbereiche und versorgen unzählige Dienste und Services mit ausreichend Rechen- und Verarbeitungskapazität. Wir erklären die Funktionsweisen des Verfahrens und stellen die verwendeten Systemarchitekturen und Anwendungsbereiche dar. Die Vorteile des verteilten Rechnens werden ebenfalls behandelt.
Was ist Distributed Computing?
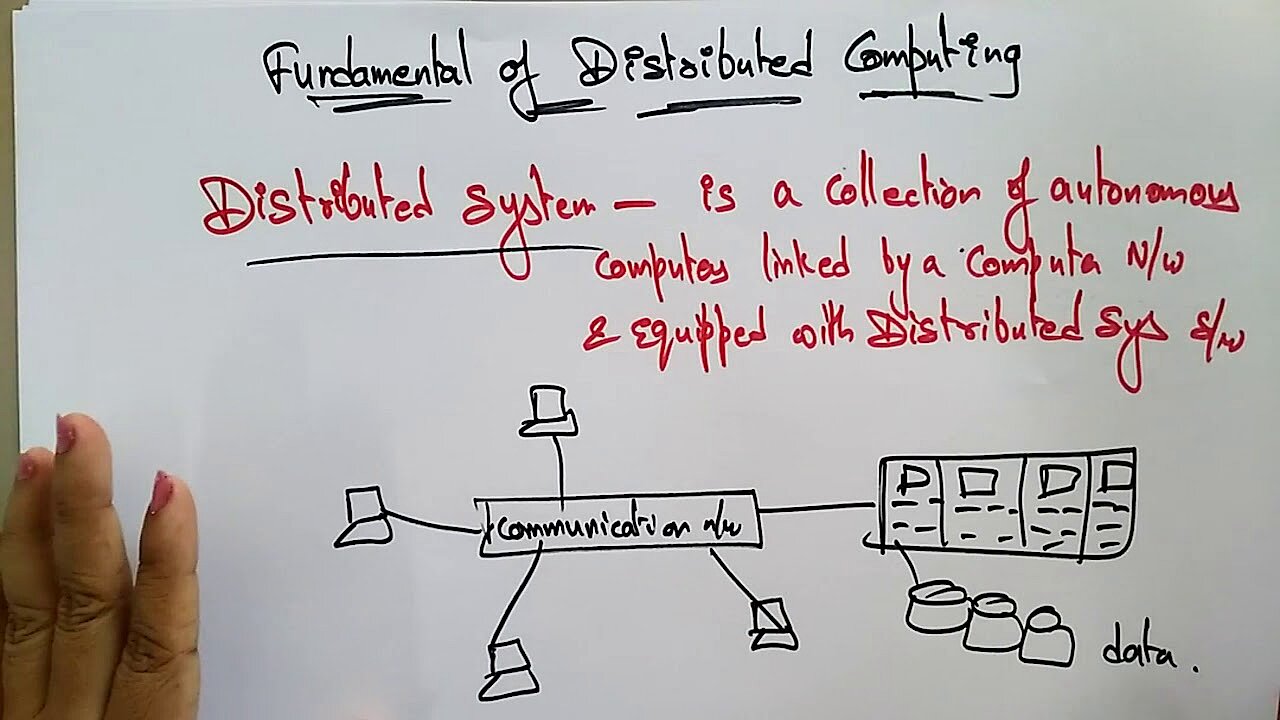
Der Begriff „Distributed Computing” bezeichnet eine digitale Infrastruktur, bei der ein Rechnerverbund anstehende Berechnungsaufgaben löst. Trotz räumlicher Trennung arbeiten die autonomen Computer in einem arbeitsteiligen Prozess eng zusammen. Für das Verfahren ist die verwendete Hardware sekundär, neben besonders leistungsfähigen Computern und Workstations aus dem professionellen Bereich können auch Minicomputer und Desktop-PCs von Heimanwendern eingebunden werden.
Da die verteilte Hardware aufgrund der räumlichen Trennung keinen gemeinsamen Speicher nutzen kann, tauschen die beteiligten Computer Nachrichten und Daten (z. B. Berechnungsergebnisse) über ein Netzwerk aus. Die intermaschinelle Kommunikation (siehe hierzu auch Was ist Machine-to-Machine-Kommunikation?) erfolgt lokal über ein Intranet (z. B. bei einem Rechenzentrum) oder überregional und global via Internet. Den Transport von Nachrichten übernehmen beispielsweise Internetprotokolle wie TCP/IP und UDP.
Distributed Computing ist im Sinne des Transparenzprinzips bestrebt, sich nach außen hin als funktionale Einheit zu präsentieren und die Bedienung der Technik bestmöglich zu vereinfachen. Anwender, die beispielsweise eine Produktsuche in der Datenbank eines Online-Shops starten, nehmen das Einkaufserlebnis als einheitlichen Prozess wahr und müssen sich nicht mit der modularen Systemarchitektur einer genutzten Infrastruktur beschäftigen.
Letztlich ist Distributed Computing also eine Kombination aus Aufgabenverteilung und koordinierter Interaktion. Das Ziel ist, die Aufgabenbewältigung möglichst effizient zu gestalten und flexible praxisnahe Lösungen zu finden.
Wie funktioniert Distributed Computing?
Ausgangspunkt einer Berechnung ist beim Distributed Computing eine besondere Strategie der Problemlösung. Ein einzelnes Problem wird unterteilt und jeder Teilbereich wird von einer Recheneinheit bearbeitet. Die operative Umsetzung übernehmen verteilte Anwendungen (Distributed Applications), die auf allen Maschinen des Rechnerverbunds laufen.
Verteilte Anwendungen nutzen häufig eine Client-Server-Architektur. Client und Server operieren arbeitsteilig und decken mit der dort installierten Software bestimmte Anwendungsfunktionen ab. Eine Produktsuche läuft in folgenden Schritten ab: Der Client agiert als Eingabeinstanz und Benutzerschnittstelle, welche die Useranfrage entgegennimmt und so aufbereitet, dass sie an einen Server weitergereicht werden kann. Der ortsferne Server übernimmt dann den Hauptteil der Suchfunktionalität und recherchiert in einer Datenbank. Das Ergebnis der Suche wird serverseitig für den Rücktransport an den Client aufbereitet und an diesen über das Netzwerk kommuniziert. Am Ende erfolgt die Ausgabe des Ergebnisses am Display des Anwenders.
In die verteilten Prozesse werden häufiger Middleware-Services eingebunden. Als spezielle Softwareschicht definiert Middleware das (logische) Interaktionsmuster zwischen Partnern und sorgt im Verteilten System für Vermittlung und optimale Integration. So werden Schnittstellen und Dienste zur Verfügung gestellt, die Lücken zwischen verschiedenen Anwendungen schließen sowie deren Kommunikation ermöglichen und überwachen (z. B. durch Kommunikationscontroller). Für eine operative Abwicklung stellt Middleware beispielsweise mit dem Remote Procedure Call (RPC) ein bewährtes Verfahren der geräteübergreifenden Interprozesskommunikation zur Verfügung, das in etwa in Client-Server-Architekturen häufig für Produktsuchen mit Datenbankabfragen genutzt wird.
Diese Integrationsfunktion, die dem Transparenzprinzip zuarbeitet, kann auch als Übersetzungsaufgabe aufgefasst werden. Technisch heterogene Anwendungssysteme und Plattformen, die normalerweise nicht miteinander kommunizieren können, sprechen sozusagen eine Sprache und arbeiten mit Hilfe von Middleware produktiv zusammen. Neben der geräte- und plattformübergreifenden Interaktion kümmert sich Middleware um weitere Aufgaben, wie die Datenverwaltung. Außerdem steuert sie den Zugriff von Verteilten Anwendungen auf die Funktionen und Prozesse der Betriebssysteme, die lokal auf den angedockten Rechnern verfügbar sind.


 Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern.
Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern.
Welche Arten von Distributed Computing gibt es?
Distributed Computing ist ein vielgestaltiges Phänomen mit teils sehr unterschiedlichen Infrastrukturen. Sämtliche Varianten von Distributed Computing sind daher kaum zu bestimmen. Dem Teilgebiet der Informatik werden aber häufiger drei Teil- bzw. Unterbereiche zugeordnet:
- Cloud Computing
- Grid Computing
- Cluster Computing
Beim Cloud Computing wird verteiltes Rechnen verwendet, um Kunden hochskalierbare und kostengünstige Infrastrukturen und Plattformen bereitzustellen. Cloud-Anbieter stellen ihre Kapazitäten meist in Form von gehosteten Diensten zur Verfügung, die über das Internet genutzt werden können. In der Praxis haben sich verschiedene Service-Modelle etabliert:
- Software as a Service (SaaS): Bei der Dienstleistung SaaS nutzt der Kunde die Anwendungen sowie die dazugehörige Infrastruktur eines Cloud-Anbieters (z. B. Server, Online-Speicher, Rechenkapazitäten). Auf die Anwendungen kann mit unterschiedlichen Geräten über ein sogenanntes „Thin Client Interface“ (z. B. eine browserbasierte Web-App) zugegriffen werden. Die Pflege und Administration der ausgelagerten Infrastruktur übernimmt der Cloud-Anbieter.
- Platform as a Service (PaaS): Bei der Dienstleistung PaaS wird eine cloudbasierte Umgebung z. B. für die Entwicklung von Webanwendungen zur Verfügung stellt. Der Kunde hat die Kontrolle über die bereitgestellten Anwendungen und kann nutzerspezifische Einstellungen vornehmen, um die technische Infrastruktur für das Distributed Computing kümmert sich der Cloud-Anbieter.
- Infrastructure as a Service (IaaS): Bei dem Service IaaS wird eine technische Infrastruktur vom Cloud-Provider zur Verfügung gestellt, auf die Anwender über private oder öffentliche Netzwerke zugreifen. Zu den Komponenten der bereitgestellten Infrastruktur gehören beispielsweise Server, Rechen- und Netzkapazitäten, Kommunikationsgeräte wie Router, Switche oder Firewalls, Speicherplatz sowie Systeme zur Archivierung und Sicherung von Daten. Der Kunde hat seinerseits die Kontrolle über Betriebssysteme und bereitgestellte Anwendungen.
Das Grid Computing orientiert sich konzeptionell an einem Supercomputer mit enormer Rechenpower. Rechenaufgaben werden aber nicht von einer, sondern von vielen Instanzen bearbeitet. Server und PCs können dabei unabhängig voneinander unterschiedliche Aufgaben übernehmen. Grid Computing kann bei der Aufgabenbewältigung sehr flexibel auf Ressourcen zugreifen. Üblicherweise stellen Teilnehmer einem Gesamtprojekt gewisse Rechenkapazitäten nachts zur Verfügung, wenn die technische Infrastruktur nicht so stark ausgelastet ist.
Ein Vorteil ist, dass schnell sehr leistungsfähige Systeme genutzt und je nach Bedarf in der Rechenleistung skaliert werden können. Für die Leistungssteigerung muss kein kostspieliger Supercomputer durch einen teuren Nachfolger ersetzt oder aufgerüstet werden.
Da Grid Computing einen virtuellen Supercomputer aus einem Cluster lose gekoppelter Computer erzeugen kann, ist es auf besonders rechenintensive Probleme spezialisiert. Das Verfahren wird häufig für ambitionierte Projekte in der Wissenschaft verwendet oder beim Entschlüsseln von kryptografischen Codes.
Cluster Computing ist von Cloud und Grid Computing nicht klar zu trennen. Der Begriff setzt allerdings allgemeiner an und bezieht sich auf alle Formen, die Einzelcomputer und ihre Rechenkapazitäten zu einem Cluster (dt. „Traube“, „Bündel“) zusammenschließen. So gibt es beispielsweise Server-Cluster, Cluster in Big Data und Cloud-Umgebungen, Datenbank-Cluster sowie Anwendungs-Cluster. Zudem sind Rechnerverbünde vermehrt am High-Performance-Computing beteiligt, das besonders anspruchsvolle Rechenprobleme löst.
Unterschiedliche Typen von Distributed Computing lassen sich zudem bestimmen, wenn man die Systemarchitekturen und Interaktionsmodelle einer verteilten Infrastruktur zugrunde legt. Aufgrund der komplexen Systemarchitekturen des Distributed Computing spricht man auch häufiger von Distributed Systems (dt. „verteilte Systeme“).
Zu den verbreiteten Architekturmodellen des Distributed Computing zählen:
- Client-Server-Modell
- Peer-to-Peer-Modell
- Schichtenmodelle (Multi-Tier-Architekturen)
- Service-orientierte Architektur (engl.: Service-oriented architecture, SOA)
Das Client-Server-Modell ist ein einfaches Interaktions- und Kommunikationsmodell im Distributed Computing. Ein Server erhält eine Anfrage von einem Client, führt entsprechende Bearbeitungsprozeduren durch und sendet eine Antwort (Nachricht, Daten, Berechnungsergebnisse) an diesen zurück.
Eine Peer-to-Peer-Architektur organisiert die Interaktion und Kommunikation des Distributed Computings nach dezentralen Gesichtspunkten. Alle Computer (auch Nodes genannt) sind gleichberechtigt und übernehmen die gleichen Aufgaben und Funktionen im Netzwerk. Jeder Rechner ist also in der Lage, als Client und als Server zu agieren. Ein Beispiel für eine Peer-to-Peer-Architektur ist die Blockchain von Kryptowährungen.
Bei der Konzeptionierung einer Schichtenarchitektur werden einzelne Aspekte eines Software-Systems auf mehrere Ebenen (engl. tier, layer) verteilt, wodurch die Effizienz und Flexibilität des Distributed Computings erhöht wird. Die Systemarchitektur, die je nach Verwendungszweck als Zwei-Tier-, Drei-Tier- oder N-Tier-Architektur ausgestaltet werden kann, ist bei Webanwendungen häufig anzutreffen.


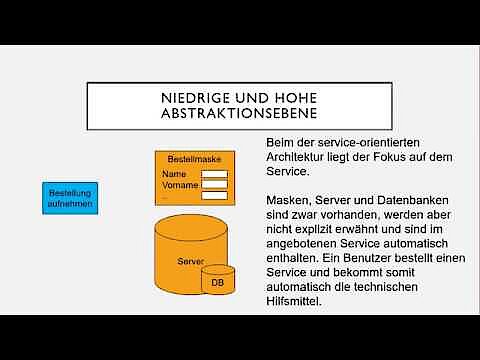
Eine serviceorientierte Architektur (SOA) stellt Dienste in den Mittelpunkt und orientiert sich dabei an den individuellen Bedürfnissen und Abläufen eines Unternehmens. So lassen sich einzelne Services zu einem maßgeschneiderten Geschäftsprozess zusammenfassen. Beispielsweise wird der Gesamtprozess „Onlinebestellung“, an dem die Services „Bestellungsaufnahme“, „Bonitätsprüfung“ und „Rechnung senden“ beteiligt sind, in einer SOA abgebildet. Technische Komponenten (Server, Datenbanken etc.) agieren als Hilfsmittel, stehen aber nicht im Vordergrund. Priorität hat bei diesem Distributed-Computing-Konzept die sinnvolle Bündelung, Zusammenarbeit und Organisation von Services mit Blick auf eine möglichst effiziente und reibungslose Abwicklung von Geschäftsprozessen.
In einer serviceorientierten Architektur wird besonderer Wert auf wohldefinierte Schnittstellen gelegt, die die Komponenten operativ verbinden und die Effizienz steigern. Letztere profitiert auch von der Flexibilität des Systems, da Dienste variabel in mehreren Kontexten eingesetzt und in Geschäftsprozessen wiederverwendet werden können. Serviceorientierte Architekturen, die auf Distributed Computing setzen, basieren häufig auf Webservices. Sie werden beispielsweise auf verteilten Plattformen wie CORBA, MQSeries und J2EE realisiert.
 Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern.
Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern.
Die Vorteile von Distributed Computing
Distributed Computing hat zahlreiche Vorteile. Unternehmen können eine leistungsfähige und bezahlbare Infrastruktur aufbauen, die anstelle extrem teurer Großcomputer (Mainframes) preiswerte handelsübliche Computer mit Mikroprozessoren nutzt. Große Cluster können sogar die Leistungsfähigkeit einzelner Supercomputer überschreiten und komplexe rechenintensive Aufgaben des High-Performance-Computings bewältigen.
Da die Systemarchitekturen des Distributed Computings aus mehreren, teils sogar redundant vorliegenden Komponenten aufgebaut sind, lässt sich der Ausfall einzelner Einheiten leichter kompensieren (erhöhte Ausfallsicherheit). Durch die hochgradige Aufgabenteilung können Prozesse ausgelagert und die Rechenlast aufgeteilt (Lastverteilung) werden.
Viele Lösungen des Distributed Computings zielen auf eine erhöhte Flexibilität, die meist auch die Effizienz und Wirtschaftlichkeit steigert. Für bestimmte Problemlösungen können gezielt spezialisierte Plattformen wie Datenbankserver eingebunden werden. Beispielsweise durch SOA-Architekturen in Geschäftsbereichen sind individuelle Lösungen möglich, die maßgeschneidert bestimmte Geschäftsprozesse optimieren. Anbieter können weltweit Rechenkapazitäten und Infrastrukturen anbieten, wodurch etwa cloudbasiertes Arbeiten möglich wird. Dabei kann auf die Bedürfnisse der Kunden mit gestaffelten und bedarfsgerechten Angeboten und Tarifen reagiert werden.
Zur Flexibilität von Distributed Computing gehört, dass etwa für besonders ambitionierte Projekte auch temporär brachliegende Kapazitäten genutzt werden können. Flexibel sind Anwender und Unternehmen auch bei der Anschaffung von Hardware, da sie nicht an einen einzelnen Hersteller gebunden sind.
Ein großer Vorteil ist die Skalierbarkeit. Unternehmen können kurzfristig und schnell skalieren oder bei kontinuierlichem organischen Wachstum die benötigte Rechenleistung schrittweise an den Bedarf anpassen. Setzt man bei der Skalierung auf eigene Hardware, lässt sich der Gerätepark in bezahlbaren Schritten kontinuierlich erweitern.
Trotz vieler Vorteile hat Distributed Computing auch einige Nachteile, etwa einen erhöhten Implementierungs- und Wartungsaufwand bei komplexen Systemarchitekturen. Zudem müssen Timing- und Synchronisationsprobleme zwischen verteilten Instanzen bewältigt werden. Hinsichtlich der Ausfallsicherheit hat der dezentrale Ansatz gegenüber einer einzigen Verarbeitungsinstanz zwar gewisse Vorteile. Gleichzeitig entstehen aus dem Verfahren des Distributed Computing aber auch Sicherheitsprobleme, etwa durch den Datentransport über öffentliche Netzwerke und deren Anfälligkeit für Sabotage und Hacking. Verteilte Infrastrukturen haben außerdem generell eine größere Fehleranfälligkeit, da es auf der Hardware- und Software-Ebene mehr Schnittstellen und potenzielle Problemquellen gibt. Die Problem- und Fehlerdiagnose ist ebenfalls durch die infrastrukturelle Komplexität erschwert.
Wo kommt Distributed Computing zum Einsatz?
Distributed Computing ist mittlerweile eine essenzielle Basistechnologie der Digitalisierung unserer Lebens- und Arbeitswelt. So wären das Internet und die dort angebotenen Services ohne die Client-Server-Architekturen verteilter Systeme undenkbar. An jeder Google-Suche ist Distributed Computing beteiligt, wenn Zulieferinstanzen auf der ganzen Welt in enger Zusammenarbeit ein passendes Suchergebnis generieren. Google Maps und Google Earth setzen bei ihren Diensten ebenfalls auf Distributed Computing.
Verfahren und Architekturen des verteilten Rechnens verwenden zudem Mail- und Conferencing-Systeme, Reservierungssysteme von Fluggesellschaften und Hotelketten, Bibliotheken und Navigationssysteme. Automatisierungsprozesse sowie Planungs-, Produktions- und Entwurfssysteme in der Arbeitswelt sind bevorzugte Einsatzgebiete der Technologie. Soziale Netzwerke, mobile Systeme, Onlinebanking und Onlinegaming (z. B. Multiplayer-Systeme) verwenden effiziente Distributed Systems.
Weitere Einsatzbereiche von Distributed Computing sind E-Learning-Plattformen, Künstliche Intelligenz und E-Commerce. Einkäufe und Bestellvorgänge in Onlineshops werden normalerweise durch verteilte Systeme unterstützt. In der Meteorologie setzen Sensoring- und Monitoringsysteme bei der Vorhersage von Katastrophen auf die Rechenkapazitäten von Distributed Systems. Viele digitale Anwendungen basieren heute auf verteilten Datenbanken.
Besonders rechenintensive Forschungsprojekte, die früher teure Supercomputer einsetzen mussten (z. B. Cray-Computer), können heute mit kostengünstigeren Distributed Systems realisiert werden. Das Volunteer-Computing-Projekt Seti@home setzte von 1999 bis 2020 Maßstäbe im Bereich des verteilten Rechnens. Zahllose vernetzte Heimcomputer von Privatanwendern werteten Daten vom Radioteleskop Arecibo in Puerto Rico aus und unterstützten die Universität Berkeley bei der Suche nach außerirdischem Leben.
Eine Besonderheit war der ressourcenschonende Ansatz: Die Auswertungssoftware arbeitete nur in Phasen, in denen die Computer der Anwender nichts zu tun hatten. Nach der Signalanalyse gingen die Ergebnisse zurück an die Zentrale in Berkeley. Vergleichbare Projekte gibt es weltweit auch an anderen Universitäten und Instituten.
Die Grundlagen von Distributed Computing werden im YouTube-Channel von Education 4u in mehreren Erklärvideos anschaulich dargestellt.
Reviewer

Christian Heldmaier
Christian Heldmaier ist ein erfahrener Online-Marketing- und SEO-Spezialist aus Karlsruhe. Seit Juli 2020 ist er als SEO Manager bei IONOS tätig.