

Kafka Tutorial

Die Open-Source-Software Apache Kafka zählt zu den besten Lösungen zur Speicherung und Verarbeitung von Datenströmen. Die Messaging- und Streaming-Plattform, die unter der Apache-2.0-Lizenz steht, überzeugt durch Fehlertoleranz, hervorragende Skalierbarkeit sowie eine hohe Lese- und Schreibgeschwindigkeit. Basis dieser für Big-Data-Anwendungen überaus interessanten Merkmale ist ein Rechnerverbund (Cluster), der es ermöglicht, Daten verteilt zu speichern und zu replizieren. Vier verschiedene Schnittstellen ermöglichen die Kommunikation mit dem Cluster, wobei ein einfaches TCP-Protokoll als Verständigungsgrundlage dient.
In diesem Kafka-Tutorial sollen die ersten Schritte mit der in Scala geschriebenen Anwendung erläutert werden – beginnend mit der Installation von Kafka und der für die Nutzung erforderlichen Software Apache ZooKeeper.
Voraussetzungen für die Nutzung von Apache Kafka
Um einen leistungsfähigen Kafka-Cluster betreiben zu können, benötigen Sie die passende Hardware. Das Entwickler-Team empfiehlt den Einsatz von Intel Xeon Maschinen mit Quad-Core und 24 Gigabyte Arbeitsspeicher. Ganz prinzipiell benötigen Sie ausreichend Speicher, um jederzeit die Lese- und Schreibzugriffe aller Anwendungen zwischenspeichern zu können, die aktiv auf den Cluster zugreifen. Da insbesondere der hohe Datendurchsatz zu den Vorzügen von Apache Kafka zählt, ist auch die Wahl der passenden Festplatten von enormer Wichtigkeit. Die Apache Software Foundation empfiehlt SATA-Festplattenlaufwerke (8 x 7200 UpM) – hinsichtlich der Vermeidung von Leistungsengpässen gilt der Grundsatz: Je mehr Festplatten, desto besser.
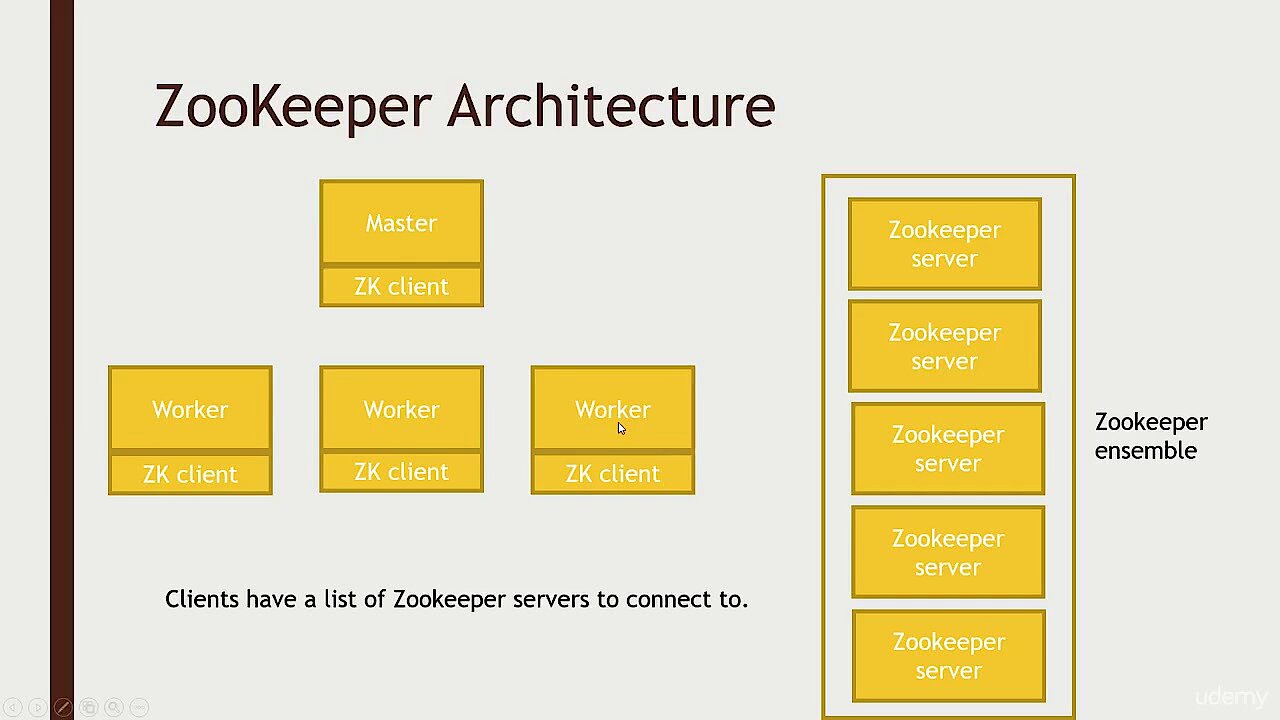
Auch hinsichtlich der Software müssen einige Voraussetzungen erfüllt werden, um Apache Kafka für das Management eingehender und ausgehender Datenströme nutzen zu können. Bei der Wahl des Betriebssystems sollten Sie beispielsweise ein UNIX-System wie Solaris oder eine Linux-Distribution bevorzugen, da Windows-Plattformen nur eingeschränkt unterstützt werden. Da Apache Kafka in der nach Java kompilierenden Sprache Scala geschrieben ist, muss außerdem eine möglichst aktuelle Version des Java SE Development Kits (JDK) auf Ihrem System installiert sein. Selbiges enthält unter anderem die Java-Laufzeitumgebung, die für das Ausführen von Java-Anwendungen benötigt wird. Eine weitere Pflichtkomponente ist der Service Apache ZooKeeper, der die Synchronisation verteilter Prozesse ermöglicht.
 Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern.
Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern. Apache-Kafka-Tutorial: So installieren Sie Kafka, ZooKeeper und Java
Welche Software-Komponenten erforderlich sind, haben wir im vorangegangenen Teil dieses Kafka-Tutorials erklärt. Sofern sie nicht bereits auf Ihrem System eingerichtet ist, beginnen Sie am besten mit der Installation der Java-Laufzeitumgebung. Viele neuere Versionen von Linux-Distributionen – wie Ubuntu, das in diesem Apache-Kafka-Tutorial beispielhaft als Betriebssystem dient (Version 17.10) – haben mit OpenJDK bereits eine kostenfreie JDK-Implementierung im offiziellen Pakete-Repository. Sie können das Java-Kit also ganz einfach über dieses installieren, indem Sie Sie folgenden Befehl in das Terminal eingeben:
sudo apt-get install openjdk-8-jdkDirekt im Anschluss an die Java-Installation fahren Sie mit der Installation des Prozess-Synchronisations-Dienstes Apache ZooKeeper fort. Auch für diesen hält das Ubuntu-Paketverzeichnis ein einsatzfertiges Paket bereit, das sich folgendermaßen über die Kommandozeile ausführen lässt:
sudo apt-get install zookeeperdMit einem weiteren Befehl können Sie anschließend überprüfen, ob der ZooKeeper-Dienst aktiv ist:
sudo systemctl status zookeeperLäuft Apache ZooKeeper, sieht das Ausgaberesultat wie folgt aus:


Läuft der Synchronisationsservice nicht, können Sie ihn jederzeit mit diesem Befehl starten:
sudo systemctl start zookeeperDamit ZooKeeper immer automatisch beim Systemstart ausgeführt wird, legen Sie zum Abschluss noch einen Autostart-Eintrag an:
sudo systemctl enable zookeeperSchließlich erstellen Sie noch ein Benutzerprofil für Kafka, das für die spätere Nutzung des Servers erforderlich ist. Öffnen Sie hierfür erneut das Terminal und geben Sie folgenden Befehl ein:
sudo useradd kafka -mMithilfe des Passwort-Managers passwd fügen Sie dem Benutzer anschließend ein Passwort hinzu, indem Sie das folgende Kommando und anschließend das gewünschte Kennwort eintippen:
sudo passwd kafkaIm nächsten Schritt gewähren Sie dem Benutzer „kafka“ sudo-Rechte:
sudo adduser kafka sudoMit dem neu erstellen Benutzerprofil können Sie sich nun jederzeit einloggen:
su - kafkaAn dieser Stelle des Tutorials ist es an der Zeit, Kafka herunterzuladen und zu installieren. Es gibt eine Reihe vertrauenswürdiger Quellen, die sowohl ältere als auch aktuelle Versionen der Stream-Verarbeitungs-Software zum Download zur Verfügung stellen. Direkt aus erster Hand erhalten Sie die Installationsdateien beispielsweise über das Downloadverzeichnis der Apache Software Foundation. Es ist sehr empfehlenswert, mit einer aktuellen Kafka-Version zu arbeiten, weshalb Sie den folgenden Download-Befehl vor der Eingabe in das Terminal unter Umständen entsprechend anpassen müssen:
wget http://www.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgzDa es sich bei der heruntergeladenen Datei um eine komprimierte Datei handelt, entpacken Sie diese im nächsten Schritt:
sudo tar xvzf kafka_2.12-2.1.0.tgz --strip 1Mithilfe des Parameters „--strip 1“ sorgen Sie dafür, dass die extrahierten Dateien direkt im Verzeichnis „~/kafka“ gespeichert werden. Andernfalls würde Ubuntu auf Basis der in diesem Kafka-Tutorial verwendeten Version alle Dateien im Verzeichnis „~/kafka/kafka_2.12-2.1.0“ ablegen. Voraussetzung ist, dass Sie zuvor mithilfe von mkdir ein Verzeichnis mit dem Namen „kafka“ erzeugt haben und in dieses gewechselt sind (via „cd kafka“).
Kafka: Tutorial zur Einrichtung des Streaming- und Messaging-Systems
Nachdem Sie nun Apache Kafka sowie die Java-Laufzeitumgebung und ZooKeeper installiert haben, können Sie den Kafka-Service prinzipiell jederzeit ausführen. Bevor Sie dies tun, sollten Sie jedoch noch ein paar kleine Konfigurationen vornehmen, damit die Software optimal für die bevorstehenden Aufgaben eingestellt ist.
Löschen von Topics freischalten
Kafka erlaubt im Standard-Set-up nicht, Topics – also die Speicher- und Kategorisierungseinheiten eines Kafka-Clusters – zu löschen, was sich jedoch problemlos über die Kafka-Konfigurationsdatei server.properties ändern lässt. Sie öffnen diese Datei, die sich im Ordner „config“ befindet, mit dem folgenden Terminal-Befehl im Standard-Texteditor nano:
sudo nano ~/kafka/config/server.propertiesAm Ende dieser Konfigurationsdatei fügen Sie nun einen neuen Eintrag hinzu, der das Löschen von Kafka-Topics freischaltet:
delete.topic.enable=true

Vergessen Sie nicht, den neuen Eintrag in der Kafka-Konfigurationsdatei zu speichern, bevor Sie den nano-Editor wieder schließen!
.service-Dateien für ZooKeeper und Kafka anlegen
Im nächsten Schritt dieses Kafka-Tutorials geht es darum, Unit-Dateien für ZooKeeper und Kafka zu erstellen, die es ermöglichen, gewöhnliche Aktionen wie das Starten, Beenden oder Neustarten der beiden Dienste passend zu anderen Linux-Services auszuführen. Dafür ist es notwendig, für beide Anwendungen .service-Dateien für den Sitzungsmanager systemd zu erstellen und einzurichten.
So erstellen Sie die passende ZooKeeper-Datei für den Ubuntu-Sitzungsmanager systemd
Erstellen Sie zunächst die Datei für den Synchronisationsservice ZooKeeper, indem Sie folgenden Befehl in das Terminal eingeben:
sudo nano /etc/systemd/system/zookeeper.serviceDadurch wird die Datei nicht nur erstellt, sondern auch gleich im nano-Editor geöffnet. Geben Sie dort nun folgende Zeilen ein und speichern Sie die Datei im Anschluss:
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetInfolgedessen versteht systemd, dass ZooKeeper erst dann gestartet werden kann, wenn das Netzwerk und das Dateisystem bereit sind, was in der Sektion [Unit] definiert ist. Unter [Service] ist spezifiziert, dass der Sitzungsmanager für den Start bzw. den Stopp von ZooKeeper die Dateien zookeeper-server-start.sh bzw. zookeeper-server-stop.sh nutzen soll. Zudem ist ein automatischer Neustart für solche Fälle definiert, in denen der Service unvorhergesehen gestoppt wurde. Der [Install]-Eintrag reguliert, wann die Datei gestartet wird, wobei „multi-user.target“ der Standard-Wert für ein Mehrbenutzersystem (z. B. einen Server) ist.
Kafka-Datei für den Ubuntu-Sitzungsmanager systemd erstellen – so funktioniert‘s
Die .service-Datei für Apache Kafka erstellen Sie mit folgendem Terminal-Kommando:
sudo nano /etc/systemd/system/kafka.serviceAnschließend kopieren Sie folgenden Inhalt in die neue Datei, die bereits im nano-Editor geöffnet wurde:
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetIm [Unit]-Bereich dieser Datei ist die Abhängigkeit des Kafka-Services von ZooKeeper spezifiziert. Somit ist sichergestellt, dass auch der Synchronisationsdienst startet, wenn die kafka.service-Datei ausgeführt wird. Unter [Service] sind die Shell-Dateien kafka-server-start.sh und kafka-server-stop.sh für das Starten bzw. Beenden des Kafka-Servers eingetragen. Der automatische Neustart nach vorangegangenem Verbindungsabbruch sowie der Mehrbenutzersystem-Eintrag sind in dieser Datei ebenfalls zu finden.


Kafka: Erster Start und Erstellen eines Autostart-Eintrags
Nachdem Sie die Sitzungsmanager-Einträge für Kafka und ZooKeeper erfolgreich angelegt haben, können Sie Kafka nun folgendermaßen starten:
sudo systemctl start kafkaDas Programm systemd verwendet standardmäßig ein zentrales Protokoll bzw. Journal, in das automatisch alle Log-Meldungen geschrieben werden. Aufgrund dieses Umstands können Sie ganz einfach überprüfen, ob der Kafka-Server wie gewünscht gestartet wurde:
sudo journalctl -u kafkaDer Output sollte in etwa folgendermaßen aussehen:


Funktioniert der manuelle Start von Apache Kafka, aktivieren Sie zum Abschluss noch den automatischen Start im Rahmen des System-Boots:
sudo systemctl enable kafkaApache-Kafka-Tutorial: Erste Schritte mit Apache Kafka
Um Apache Kafka zu testen, soll an dieser Stelle des Kafka-Tutorials eine erste Nachricht mithilfe der Messaging-Plattform verarbeitet werden. Zu diesem Zweck benötigen Sie einen Producer und einen Consumer – also eine Instanz, die das Schreiben und Veröffentlichen von Daten in Topics ermöglicht, sowie eine Instanz, die Daten eines Topics auslesen kann. Zuerst erzeugen Sie allerdings das Topic, das in diesem Fall den Namen TutorialTopic erhalten soll. Da es sich um ein einfaches Test-Topic handelt, soll es lediglich eine einzelne Partition sowie eine einzige Replik enthalten:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TutorialTopicIm zweiten Schritt erstellen Sie einen Producer, der dem gerade kreierten Topic die erste Beispiel-Nachricht „Hallo Welt!“ hinzufügt. Zu diesem Zweck nutzen Sie das Shell-Skript kafka-console-producer.sh, das den Hostnamen und den Port des Servers (im Beispiel: Kafka-Standardpfad) sowie den Namen des Topics als Argumente erwartet:
echo "Hallo Welt!" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic > /dev/nullMithilfe des Skripts kafka-console-consumer.sh erzeugen Sie abschließend einen Kafka-Consumer, der Nachrichten von TutorialTopic verarbeitet und wiedergibt. Als Argumente werden wiederum Hostname und Port des Kafka-Servers sowie der Topic-Name benötigt. Zudem wird das Argument „--from-beginning“ angehängt, damit die „Hallo Welt!“-Nachricht, die in diesem Fall noch vor dem Start des Consumers veröffentlicht wurde, auch tatsächlich von diesem verarbeitet werden kann:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TutorialTopic --from-beginningAls Folge präsentiert das Terminal die „Hallo Welt!”-Nachricht, wobei das Skript kontinuierlich weiterläuft und auf weitere Nachrichten wartet, die zu dem Test-Topic veröffentlicht werden. Sorgen Sie also durch den Producer in einem anderen Terminalfenster für weiteren Daten-Input, sollten Sie diese ebenfalls im Terminalfenster sehen, in dem das Consumer-Skript ausgeführt wird.

